My Ceph Cluster runs now! And it is amizingly powerful 🙂
Updates for Ceph Reef. Quincy is not yet the latest release anymore, I reinstalled my cluster with Reef (now using 6 Odroid HC4s each with a single 4TB disk) and updated this blog post.
Quite some time has passed since my last tries to get a ceph cluster running on ARM and compiling it on 32-bit ARM. But with every unsolved problem, moles are not well known to forget about unfinished tunneling projects. It’s again time to blast the solid rock with some pieces of dynamite 🙂 Ah, wrong project… we are under water not below ground… (do not get confused… octopus was a release of ceph and v17.2 aka. quincy is the latest version as of writing this)
I purchased three ODROID HC4 (the P-Kit) quite some weeks ago. It has a 64 bit ARM core, 4 GB of RAM and two slots for hard drives. And the drives I bought some years ago (4TB WD Red Standard) are still not continuously used and I could get two of them for use in my cluster. They just served to keep some data temporarly. I bought now another four pieces of WD Red (this time the Pro) and assembled it with the two remaining HC4-P Kits. So I have now three pieces of HC4 containing six WD Red hard drives in total, which means 24 TB of raw capacity.


As you may guessed already, installing ceph is still not an easy task. You can often not simply stick to the manual and this is, why I started writing again. In fact, I took two long ways without success out of many more wrong ways, that ended very quickly. And here is the way, that was successful, with only minor headaches to crush.
Installation
After trying different things (original HC4, debian bullsey stable and unstable), I got over to try armbian for ODROID HC4 (Bookworm CLI as of Nov, 30th 2023). It is based on debian and provides recent updates (currently containing ceph 16.2.11, but ceph provides latest packages for debian bookworm). Flashing is easily done with Balena Etcher.
Hardware Preparation
But to get it running, you need to get rid of petitboot, preinstalled on HC4 SPI flash. The instructions mentioned on the armbian page were not working. With latest kernel, the MTD devices do not show up any longer in the booted system (reached by holding the bottom button of HC4 and powering on) and also petitboot did not show up when a monitor was connected. I don’t know exactly why, but I soon took out the screws from the case and connected the UART (115200 8N1). Fortunately, I had an original ODROID USB-serial converter (aka. USB-UART 2 Module Kit) at hand.
After power up, a minimal system presented itself on the console (most obviously, this is petitboot). So i issued the commands to erase the SPI flash:
$ flash_eraseall /dev/mtd0
$ flash_eraseall /dev/mtd1
$ flash_eraseall /dev/mtd2
$ flash_eraseall /dev/mtd3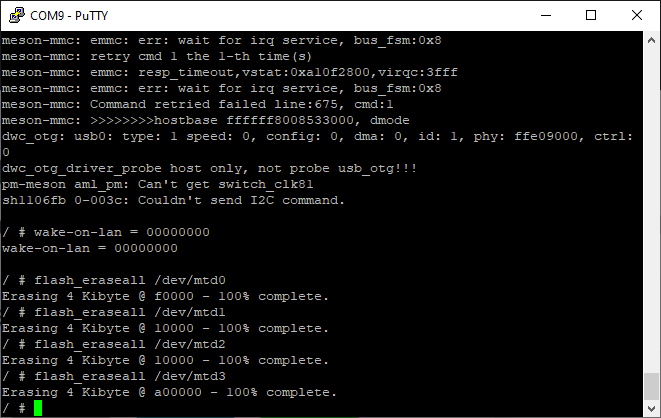
This took (especially for /dev/mtd3) a few minutes… After re-powering the board, all went fine and the system from SD-Card came up. Keep the serial console connected or log in via SSH (user:root/pass:1234) and follow the initial installation wizard, initializing username, passwords, default shell and locales.
Prepare the Linux System
Now update the system, change the hostname and reboot:
$ apt update
$ apt upgrade -y
$ apt install -y vim
$ hostname <YOUR_HOSTNAME>
$ hostname > /etc/hostname
### On the HC4
$ sed -i "s/odroidhc4/$(hostname)/" /etc/hosts
### On a pi4b
$ sed -i "s/pi4b/$(hostname)/" /etc/hosts
$ sed -i "s/^.*\(SIZE\)=.*$/\1=256M/" /etc/default/armbian-ramlog
$ rebootFor getting a nice status on OLED, you can easily install sys-oled-hc4 as a user with sudo permissions:
$ git clone https://github.com/rpardini/sys-oled-hc4
$ cd sys-oled-hc4
$ sudo ./install.sh
$ sudo sed -i "s/eth0/end0/" /etc/sys-oled.conf
# or
$ vi /etc/sys-oled.conf # Change network interface to end0To bring a bit of color into life (and to quickly see, if you are root or somebody else)
$ sudo curl --silent \
-o /root/.bashrc \
https://raw.githubusercontent.com/the78mole/the78mole-snippets/main/configs/.bashrc_root
$ curl --silent \
-o ~/.bashrc \
https://raw.githubusercontent.com/the78mole/the78mole-snippets/main/configs/.bashrc_user
$ sudo cp ~/.profile /root/Now continue installing the real ceph stuff 🙂
Additionally I prepared a Rapspberry Pi 4 also with armbian CLI aka Bookworm… I’ll use cephadm in the curl-installation version to deploy my cluster, sticking to the official documentation.
Install Ceph on the Master Node (RPi 4)
On the master node, you should install a jammy CLI since the cephadm package is not existant in for this version of ceph and it will install v16 (precise) instead of reef.
$ sudo apt install podman catatonit lvm2
$ CEPH_RELEASE=18.2.1 # replace this with the active release
$ curl --silent --remote-name --location https://download.ceph.com/rpm-${CEPH_RELEASE}/el9/noarch/cephadm
$ chmod +x cephadm
$ sudo ./cephadm add-repo --release reef
#### You can check, if ceph is the desired version with
### apt search cephadm
$ sudo ./cephadm install
$ ip a # Wathc out for your IP address
$ sudo cephadm bootstrap --mon-ip <THIS_SYSTEMS_NETWORK_IP>After bootstrap, open a ceph shell and add a new administrative user (do not use admin, it is already used, disable it later).
$ cephadm shell
$ vi passwdfile.txt # Enter your new password there
$ ceph dashboard ac-user-create <USERNAME> -i ceph-adm-passwd.txt administratorOn every host you want to include in your cluster, you need to install following packages (I did this all with ansible, maybe I’ll write some post about it in the future -> Leave me a comment if you are interested):
$ apt install podman catatonit lvm2 gdisk Installing Ceph using cephadm
Cephadm helps a lot to bootstrap a ceph cluster by preparing the host (also the remote hosts) from one single point in your network/cluster. What I learned painfully is, if you have a mixed architecture (arm64/aarch64 and amd64/x86_64), you should not start deploying your cluster from some amd64 machine. To read, why this is the case, just drop down the accordeon:
Why a ceph roll-out fails when starting on amd64 (klick if you want to read more)
When starting from amd64, it will install perfectly on your amd64 hosts and will also install some of the services (docker/podman containers) on your arm64, but also a few services will just fail. A first look in their quay repo revealed, that it has images for arm64 and amd64. But if you dig deeper, you can see, that arm64 build actions failed on GitHub. Applied to our case, this could mean, that arm64 machines will build their own images, when starting roll-out on arm64, but they will receive a wrong image hash, when starting cephadm on amd64. If you go back in history of the ceph container builds, you can see, that 2 years ago, the build was working (last ceph version on docker hub is 16.2.5), just before they switched hosting their repos from docker hub to quay.io. I believe, this is because red hat took over the ceph and quay.io is a red hat product. I somewhere read, that quay can not host images for different architectures in parallel, but I stopped digging here…
It seems, if you just start deployment from some arm64 machine, it works like a charm :-).
As a preparation for your deployment, you are well advised to distribute the SSH pubkey to all hosts you want to include in your cluster. This is quite easy… We will use the root user and an ssh-key without password, since it makes things way easier…
$ sudo -i
$ ssh-keygen -t ed25519 # No password, just press enter two times
### If you want a password protected key, have a look at keychain that makes
### managing ssh keys with an ssh-agent easy
$ ssh-copy-id root@<CLUSTER_HOST1>
$ ssh-copy-id root@<CLUSTER_HOST2>
...We also need to deplay ceph’s ssh key to the hosts. To get the key, you need to execute a ceph command:
$ cephadm shell -- ceph cephadm get-pub-keyTake the line starting with ssh-rsa and add it to the /root/.ssh/authorized_keys file on each host.
Now we can kick-start our cluster. I used a little Raspberry Pi4 (4GB RAM) running armbian jammy. You could also use a ODROID-C4. For just doing the manager-stuff, a little RPi3 with 1GB RAM would also be enough. I’ll move the heavy tasks (mon, prometheus, graphana,…) to a VM on my big arm64 server in a VM with 8 GB RAM. So the Pi only has to do some easy tasks until it is replaced by some Pi4 with 8GB RAM, as soon as they are available again.
To sow the seed, issue the following command:
$ sudo cephadm bootstrap \
--mon-ip $(ip route get 1.1.1.1 | grep -oP 'src \K\S+')Now you are done with the initial step… You can log in using the hostname and the credentials as shown. If localhost is shown as the URL, simply replace it by the IP or the hostname of your mgr daemon.
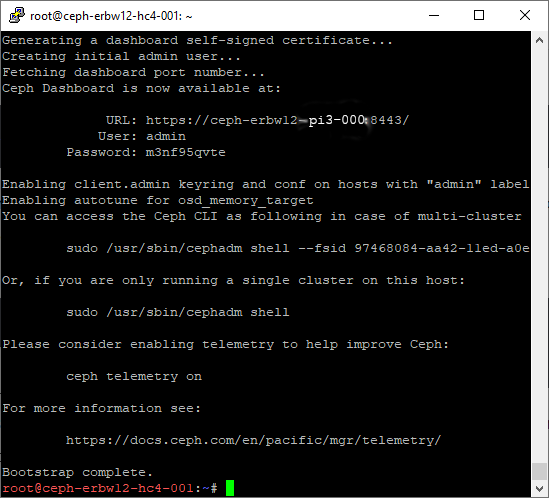
Then log in to the web UI.

Now you are asked to provide a new password and re-login.
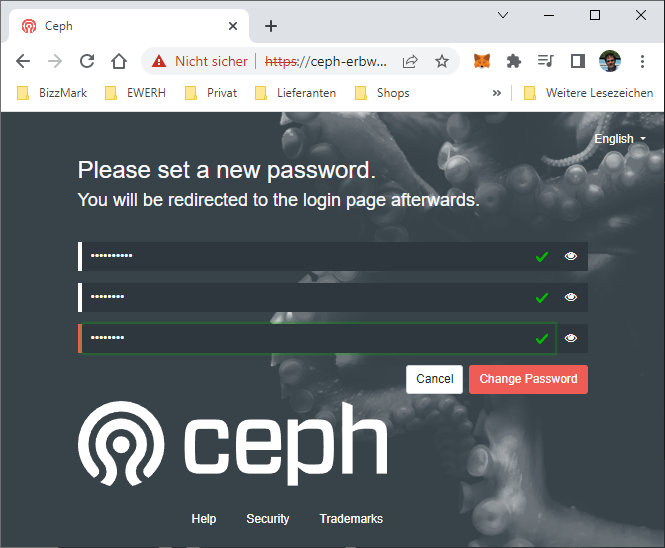
Ceph should greet you with the following screen. Just ignore the Expand Cluster…

Now go to Cluster -> Hosts. There should be only a single host, the mgr (with mon) you just bootstrapped.
Now head over to your other hosts with ssh and prepare the HDDs for use as OSD storages. You will scrub the partition table on it with the following command.
$ sgdisk --zap-all /dev/sda /dev/sdb <...>This should help, getting it prepared as OSDs.
Now head over to your ceph web UI again and select Add... in the hosts section.
TODO some Screenshots
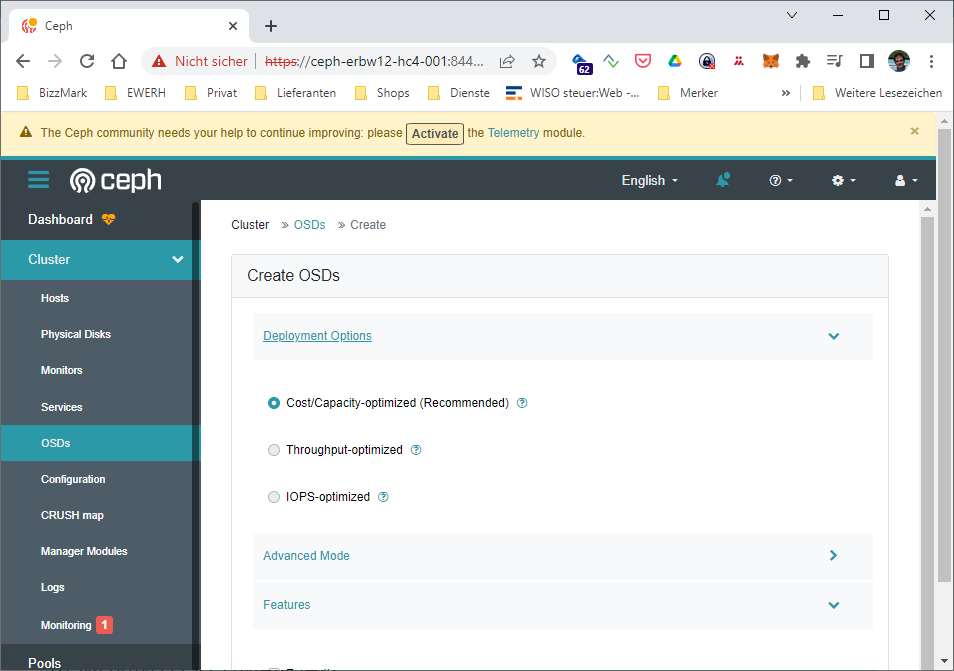
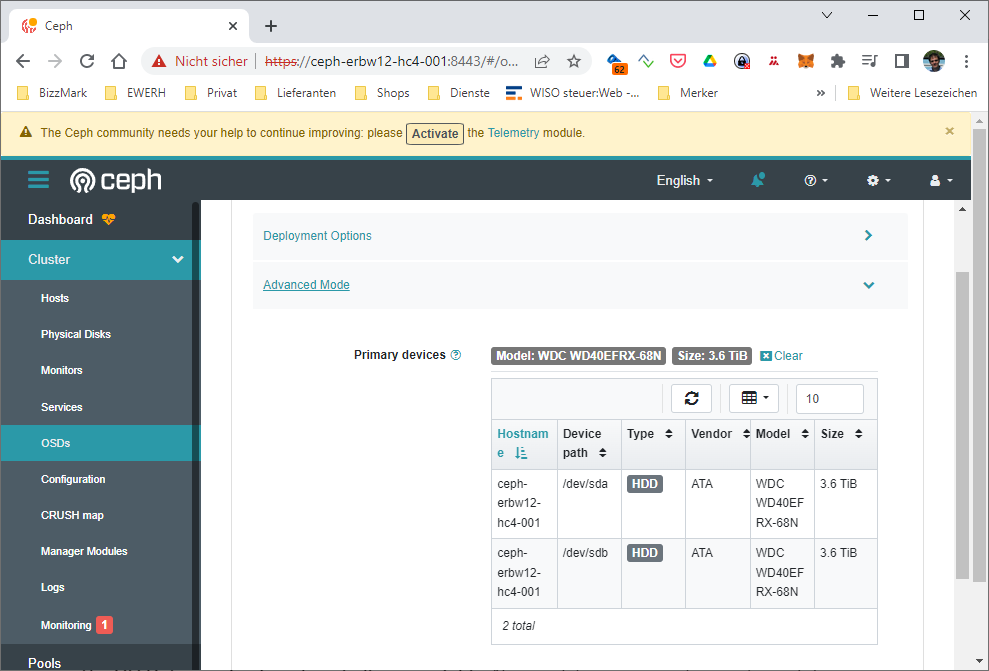
I took the model as a filter, so every HDD with the same model string on every HC4 get simply added when ceph is bootstrapping the host. Since we do not have SSDs or NVMes, it makes no sense to define WAL or DB devices… They are also not available here 🙂
We then can add services to this host.
Now distributing some daemons over the cluster.
TODO
- Using labels to define the hosts to run services on
- Making Graphana and Prometheus work (SSL issues with self signed certificate)
- Creating and mounting a CephFS
- Using the object store (Swift and S3)
- Some more details and hints on the HW infrastructure
- Adjusting the CRUSH map
- Creating own certificates (create a new tutorial post)
Creating a CephFS
Creating a CephFS with Replication
Easiest and most secure way to create a CephFS is to use two replication. Usually ceph stores Data with a redundancy of 3, meaning, it will create 2 copies of your data striped accross failure domains (usually hosts). In my setup with 3 hosts (each with 2 OSDs), this is the maximum.
The easiest solution, is to simply create the CephFS and let it implicitly create your pools and strategies.
$ cephadm shell
$ ceph fs volume create <NAME_OF_FS>Thats all with creating it 🙂
To mount it, you need to create a keyring:
$ ceph auth get-or-create client.<CLIENT_NAME> \
mon 'allow r' \
mds 'allow r, allow rw path=/' \
osd 'allow rw pool=erbw12-bigdata-fs' \
-o /root/ceph.client.<CLIENT_NAME>.keyring
$ ceph fs authorize <NAME_OF_FS> client.<CLIENT_NAME> / rwNow, cat the keyring and copy paste the content to /etc/ceph/ceph.client.<CLIENT_NAME>.keyring to the host, where you want to mount your CephFS. Now go to this other host, install ceph-fuse package and execute the following:
$ sudo -i
$ mkdir /etc/ceph
$ cd /etc/ceph/
$ ssh-keygen -t ed25519
$ ssh-copy-id root@<CEPH_MON_HOST>
$ scp root@<CEPH_MON_HOST>:/etc/ceph/ceph.conf .
$ echo "<YOUR_COPIED_KEYRING>" > ceph.client.<CLIENT_NAME>.keyring
# another way is to get the key through ssh from the client
# host if your ceph command is accessible outside of the shell container
$ ssh root@<CEPH_MON_HOST> ceph auth get client.<CLIENT_NAME> \
> ceph.client.<CLIENT_NAME>.keyringNow you can mount your CephFS
$ mkdir <YOUR_MOUNT_POINT>
$ ceph-fuse -n client.<CLIENT_NAME> none \
-m <CEPH_MON_HOST> <YOUR_MOUNT_POINT>You can then check, if everything worked (df -h or mount) and put your data in
Creating a CephFS with Erasure Coding
Creating a pool with erasure code as data pool, you need to create the fs a bit more manually. First create your pools using the web UI.
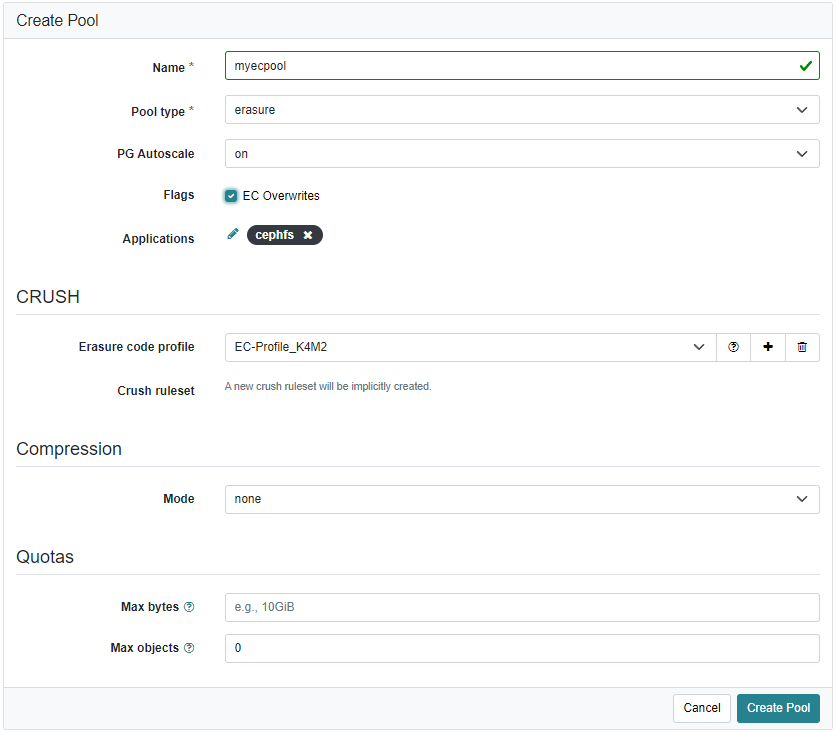
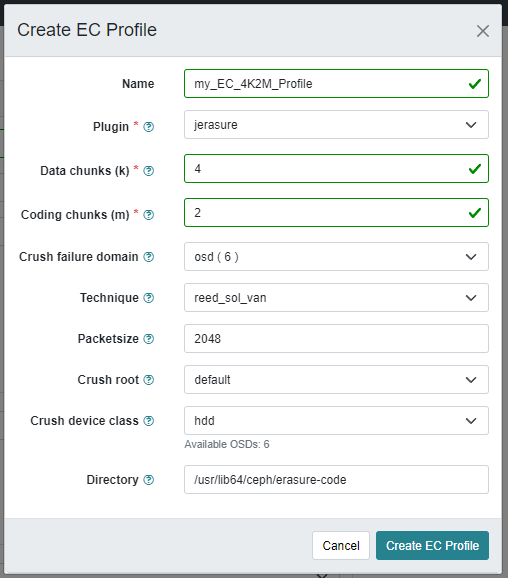
If you want to use EC for CephFS, checking the EC Overwrites is mandatory. Otherwise, Ceph will not accept the pool for cephfs. As the EC profile, you need to keep your cluster in mind. The following example will not work on a 3 node cluster (my one has only 3 failure domains = 3 hosts).
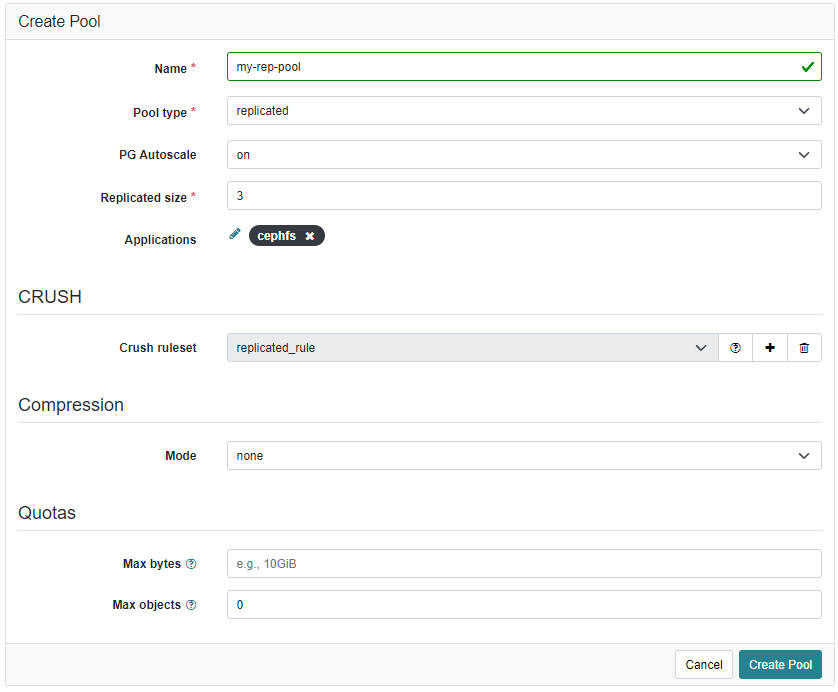
You also need to create a replication pool for the CephFS metadata.
On the cephadm shell, now issue the following commands:
$ ceph fs new <FS_NAME> <META_POOL_NAME> <DATA_POOL_NAME>For authorization, refer to the stuff in replication pool above.
Mounting the CephFS
In this example, we will mount the root of the ceph file system on a client. If you want to restrict the access to the filesystem, you need to change / with the path you want to mount on the client.
First, we need tp create a client secret. This can easily be done with the following command:
$ cephadm shell
$ ceph fs ls
...list of your fs-es...
$ ceph fs authorize <FS_NAME> client.<SOME_NAME> / rw
[client.<SOME_NAME>]
key = acbdef....xyz==
$ ceph auth get client.<SOME_NAME> >> /etc/ceph/ceph.client.<SOME_NAME>.keyring
### Now copy ceph.conf, ceph.pub and ceph.client.<SOME_NAME>.keyring from
### /etc/ceph to your client's /etc/ceph/ folderSince getting the latest cephfs fuse package on recent distributions is not the easiest way, I prepared a docker container to get it up and running quickly here. If you want to install it natively on your host, then just follow the instructions on the Ceph pages here. I suggest to use the ceph-fuse, since it does not involve kernel modules and you can select the same ceph version as your cluster runs easily.
Editing the CRUSH map
If you want to distribute your cluster physically over different locations or rooms and want to also pin your failure domains to it, you need to change the CRUSH map. Therefore, you need to add the buckets with certain types (usually region, datacenter, room,… see here for a list of predefined bucket types). After adding, you need to „move“ them to the correct locations. How this is done, is described here and finally move the osds over to the appropriate buckets.
To avoid any wired problems, you should follow this process:
- make sure ceph is HEALTH_OK
ceph osd set nooutceph osd set norebalance- edit crush map
- wait for peering to finish, all PGs must be active+clean
- lots of PGs will also be re-mapped
ceph osd unset norebalanceceph osd unset noout
To edit the crush map, you can use the following commands (see here):
$ cephadm shell
$ ceph ceph osd getcrushmap -o crushmap.bin
$ crushtool -d crushmap.bin -o crushmap.txt
### view and possibly edit the map and save it as crushmap_new.txt
$ crushtool -c crushmap_new.txt -o crushmap_new.bin
$ ceph osd setcrushmap -i crushmap_new.binAdditional Hints
Setting the minimal ceph version
For many new features, you need to restrict your cluster to a certain minimum version of ceph. To do so, check and set the minimum required versions with the following commands (in my example I run reef on all nodes):
$ cephadm shell
$ ceph osd get-require-min-compat-client
luminous
$ ceph osd set-require-min-compat-client reefWith this setting, you can e.g. use the read balancer optimization features of reef (ceph balancer mode <read|upmap-read>).
Adjusting mgr Host Distribution (1+ mgrs)
I struggled quite heavily to find out, how mgr daemons get distributed across the hosts and never was happy with it. Every time, I entered (in cephadm shell)
ceph orch apply mgr <host_to_add>The manager daemon just hopped over to the host I want to apply. I could not find a solution, how to get two managers back in again and also Chat-GPT could not help. Out of frustration I tried to add more than one host name at the end of the command and it lead to success:
ceph orch apply mgr <host1>,<host2>To ensure, that mgr with dashboard is running on the right host, just execute the command with the single host first and then run it again with all managers you want to run. This ensures, that the already running mgr is the current active one.
Unfortunately, I could not find a way to make the dashboard available on the other hosts. If you ask ceph mgr services it always shows the old address, if the active mgr jumped to a different host. cephadm itself seems to know, where the mgr is running.
Also keep in mind, that it is suggested to have managers running on hosts that also serve as monitors (mon), according to the ceph administrators docs.
Maintenance (e.g. rebooting a host)
If you want to do some maintenance, e.g. simply rebooting a host with one or more running osds, you should first tell ceph to not compensate for the missing osd. So you can follow this procedure
$ cephadm shell
$ ceph osd set noout
$ ceph osd set norebalance Then execute the stuff you want, e.g. sudo reboot on the osd host and when all daemons are back in ceph, get back to normal operation mode
$ ceph -s
#### Check if everything is fine...
$ ceph osd unset noout
$ ceph osd unset norebalanceTroubleshooting
PGs not remapping
If you changed your crush map (e.g. introducing another root and moving osds over to the new root), it can happen, that it can not shift over the placement groups and ceph -s shows all PGs as active+clean+remapped but backfilling never happens.
You can identify the problem by fist listing your PGs and then inspecting the PG in detail
$ ceph pg ls
....
5.17 (just an example in your output)....
...
$ ceph pg map 5.17
osdmap e230 pg 5.17 (5.17) -> up [2147483647,2147483647,2147483647,2147483647,2147483647,2147483647] acting [0,1,2,3,5,4]The high numbers (2147483647) indicate, that the PG is not mapped to any OSD but they still belong to the acting ones 0,1,2,3,4 & 5 (the order is not relevant).
To solve this, you need to edit the crush map. Unfortunately, there is only a CLI command to change the device-class, but not any to change the crush map root or leaf to select.
$ cephadm shell
$ ceph osd getcrushmap -o crush.map
25 # This number is the epoch of your map...
# You can use it to identify your changes
$ crushtool -d crush.map -o crush.25.map.txt
$ cp crush.25.map.txt crush.26.map.txt
$ vi crush.26.map.txt # Edit the lines with "default",
# the old name of the crush root in itEdit the crush map…
...
# buckets
root default {
id -1 # do not change unnecessarily
id -2 class hdd # do not change unnecessarily
# weight 0.00000
alg straw2
hash 0 # rjenkins1
}
# ...
# I have many other leafs here for zone, region, rooms,...
# ...
root root-mole {
id -19 # do not change unnecessarily
id -20 class hdd # do not change unnecessarily
# weight 21.83212
alg straw2
hash 0 # rjenkins1
item reg-europe weight 21.83212
}
rule replicated_rule {
id 0
type replicated
# step take default # <--- This is the 1st old line
step take root-mole # ...changed to this
step chooseleaf firstn 0 type host
step emit
}
rule Pool_EC_k4m2 {
id 2
type erasure
step set_chooseleaf_tries 5
step set_choose_tries 100
# step take default class hdd # <--- This is the 2nd old line
step take root-moles class hdd # ...changed to this
step chooseleaf indep 0 type host
step emit
}Then execute the commands to make it active
$ crushtool -c crush.26.map.txt -o crush.26.map
$ ceph osd setcrushmap -i crush.26.mapIf you did no typo or any other mistake, it should soon start to remap the PGS and show you something similar to the following:
$ ceph pg map 5.17
osdmap e242 pg 5.17 (5.17) -> up [2,4,0,1,3,5] acting [0,1,2,3,5,4]Stray Daemon
Sometimes it happens, that Ceph is complaining (warning) about a stray host with a stray daemon. This can be solved by executing the ceph health detail command in a ceph shell and then, when you found the daemon that is raising this, just stop and disable its system service.
$ cephadm shell
$ ceph health detail
HEALTH_WARN 1 stray host(s) with 1 daemon(s) not managed by cephadm
[WRN] CEPHADM_STRAY_HOST: 1 stray host(s) with 1 daemon(s) not managed by cephadm
stray host ceph-erbw12-pi4-000 has 1 stray daemons: ['mds.FS_ECK4M2_BigSpace.rpi4b.diosuz']
Then log in on your host with the stray daemon.
$ systemctl status ceph-...@mds.FS_ECK4M2_BigSpace.rpi4b.diosuz.service
● ceph-...@mds.FS_ECK4M2_BigSpace.rpi4b.diosuz.service - Ceph mds.FS_ECK4M2_BigSpac>
Loaded: loaded (/etc/systemd/system/ceph-...@.service; enabled; vendor preset:>
Active: active (running) since Fri 2024-02-09 01:54:00 CET; 2 days ago
...
Just stop and disable it
$ systemctl status ceph-...@mds.FS_ECK4M2_BigSpace.rpi4b.diosuz.service
$ systemctl disable ceph-...@mds.FS_ECK4M2_BigSpace.rpi4b.diosuz.serviceIf you then ask for the healt in the ceph shell, you will get a HEALTH OK
$ ceph health detail
HEALTH_OK
Graphs do not show up in dashboard
If your graphs on the dashboard page are empty, then the server_addr, ssl_server_port and possibly server_port are not set correctly. You can fix this on the ceph shell
$ cephadm shell
$ ceph config get mgr mgr/dashboard/server_addr
:: # This shows when nothing is configured
# Now set it to the address you access the dashboard
$ ceph config set mgr mgr/dashboard/server_addr <YOUR_DASHBOARD_IP>
$ ceph config set mgr mgr/dashboard/ssl_server_port 8443 # this is the defaultPerformance Graphs not showing (Grafana Problem)
Here I currently have no solution, but I’ll update it as soon as I have one…
Ceph Node Diskspace Warning
This warning can be mostly ignored and it is not documented anywhere in the helt check documentation. The warning araises because Armbian is using a RAM-log (/var/log) that get’s rsynced to HDD (SD card on /var/log.hdd) every day. It is also rotated, compressed and purged on the card daily. This warning will usually be resolved automatically, especially with the 256M ramlog setting (40M was armbian default) and should not pop up to often or only after setting up the cluster, while a huge amount of loggin is created.
If the problem persists, you could dive into details using the healt check operation documentation.
Manager crashed
After one day of runtime, ceph GUI reported a crash of the manager daemon. To inspect this, you need the ceph command, which is included in ceph-common, we installed previously without a need at that time. But for administrative purposes, it is quite handy 🙂
To inspect the crash, we will first list all crashes (not only new ones):
$ ceph crash ls
## Alternative to show only new crashes
$ ceph crash ls-newWe will now get a detailes crash report.
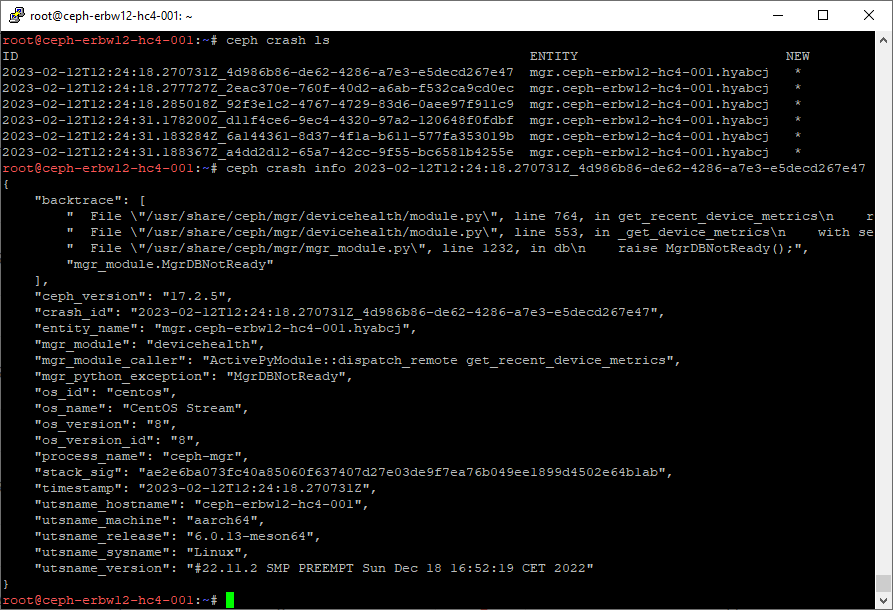
In my case, I’m not sure, if this is just a side effect of the Healt-Warn state of the cluster, not being able to pull device metrics. We will see, if it persists 🙂
To get rid of the warning, just issue an archive command
$ ceph crash archive <ID>
# Or to archive all listed (not showing up in ls-new)
$ ceph crash archive-allTo delete older crashes (and also remove them from ceph crash ls), issue the following command.
$ ceph crash prune <OLDER_THAN_DAYS>
$ ceph crash prune 3 # Will remove crashes older than 3 daysThe OLED does not yet work on bullseye unstable
Now update your repository cache and do an upgrade of the system. You should also change your timezone settings for the OLED of the HC4 to show the correct local time.
$ apt update
$ dpkg-reconfigure tzdata
$ apt upgrade
#### if using the ODROID HC4
$ apt install odroid-homecloud-display wget curl gpg jq
$ rebootI struggeled a lot to install ceph on the ARM64 ODROID HC4… Here are my misleaded tries
$ mkdir -m 0755 -p /etc/apt/keyrings
$ curl -fsSL https://download.docker.com/linux/debian/gpg | \
sudo gpg --dearmor -o /etc/apt/keyrings/docker.gpg
$ echo \
"deb [arch=$(dpkg --print-architecture) \
signed-by=/etc/apt/keyrings/docker.gpg] \
https://download.docker.com/linux/debian \
$(lsb_release -cs) stable" | \
sudo tee /etc/apt/sources.list.d/docker.list > /dev/null
$ apt update
$ apt-get install docker-ce docker-ce-cli containerd.io \
docker-buildx-plugin docker-compose-plugin
$ sudo docker run hello-worldWe need to build ceph ourself, because the packages do not contain many of the needed packages. Alternatively, you can run the management node on some x86 and only use arm64 for the OSDs.
$ git clone https://github.com/ceph/ceph.git
# or
$ git clone https://github.com/the78mole/ceph.git
$ git checkout quincy-release
$ ./install-deps.sh
$ cd ceph
# To prepare a release build... Takes some minutes
$ ./do_cmake.sh -DCMAKE_BUILD_TYPE=RelWithDebInfo
$ cd build
# Next step will take many hours (maybe some days)
$ ninja -j1To be able to distribute the packages (we will need more than a single host for ceph to make any sense), we will setup a debian package repository. I will make mine public so you can skip the process of compiling your packages. I used a german tutorial on creating an own repository, a tutorial to host a package repository using GitHub Pages and PPA repo hosted on GitHub.
$ mkdir ~/bin && cd ~/bin
$ curl --silent --remote-name --location \
https://github.com/ceph/ceph/raw/quincy/src/cephadm/cephadm
#### or # wget https://github.com/ceph/ceph/raw/quincy/src/cephadm/cephadm
$ chmod +x cephadm
$ cp cephadm /usr/sbin
#### On arm64, the cephadm package is not available, even if we have this
#### python script already at hand. Therefore, we put it in /usr/sbin and
#### fake the package to be installed with equiv. Don't do this on other
#### non-ARM systems
#### vvvv Dirty Hack Start vvvv
$ apt install equivs
$ mkdir -p ~/equivs/build && cd ~/equivs
$ curl --silent --remote-name --location \
https://raw.githubusercontent.com/the78mole/the78mole-snippets/main/ceph/cephadm-17.2.5-1.equiv
$ cd build
$ equivs-build ../cephadm-17.2.5-1.equiv
$ dpkg -i cephadm_17.2.5-1~bpo11+1_arm64.deb
#### ^^^^^ Dirty Hack End ^^^^^
#### If someone feels responsible to fix the real cephadm package for
#### all arches (it is a python tool !!!), please do it :-)
$ cephadm add-repo --release quincy
$ apt update
$ cephadm install
$ which cephadm # should give /usr/sbin/cephadm
# Tweak needed for cephadm is to enable root login over SSH
$ sed -i \
's/#PermitRootLogin.*$/PermitRootLogin yes/' \
/etc/sshd_config
$ service ssh restart
Schreibe einen Kommentar