
Motivation
In my vacations, I kicked-off some new projects. One of it is an ARM64 based SBC with integrated SATA mostly like the Odroid-HC1/2. The main difference is the ARM (64 vs. 32 Bit) to be able to run Ceph on it.
If you read some of my previous posts, you will notice, that I already put in some effort to make Ceph run on 32-bit controllers. But the effort was way to high, to make and keep it running. But the new SBC is another story, I will tell, when the time is ripe for it.
When I thought of putting all my data on a Ceph cluster, I just stumbeld over the probem, how to manage all these bits and bytes and how to keep the overview. The should be something like a Google-Search for your private data. When you dig through the net, you will find many sites, blogs and books about elastic search. But there is always a problem, how to get your data in there without a deep knowledge on data providers, ETL, graphs,… But you could also find OpenSemanticSearch (OSS) and I gave it a try.
A Private Search Engine – Open Semantic Search
To be honest, OpenSemanticSearch is not the most beatiful engine you could think of, but it gives you a very deep insight on your data, assuming you configured it correctly. Unfortunately, the documentation is quite sparse and there have not been many bloggers writing on the topic, at least not for some current version of it.
After you finished Installation, first do some deeper configuration. If you choose to use a VM, I suggest, to usa a RAM centric configuration. Better take 12+ GB of RAM and only 4 cores. Every core will lead to an etl-task that eats up a significant amount of RAM, depending on the data it is advised to index.
To avoid links of the WebUI to point you to some unreachable destination, do some configuration ahead of adding local crawler paths. If you mount your data using mount to a path in your filesystem on the OSS server, the link will be provided unchanged (e.g. /mnt/myData) and the URL will just be the location it is on your server without http, hostame, location-suffix,… Not really helpful, if you have mounted NFS shares and want to access it on a remote windows machine.
OSS provides already some document server, that proxies your requests to HTTP, but you need to configure it correctly. But if you do not configure it in the beginning, your whole indexing run will create wrong links and it will be hard to stop the indexing and do a rerun (see the troubleshooting section below). The task will be running, until it has done it’s job. For terabytes of data, this will last at least some days.
Installation and Configuration of OSS
Installation of OSS is quite straight forward, as described on their web page.
Configuration is a bit more complex due to the fact, that the documentation is a bit sparse. Some of it can be done with the web UI, but others are a bit more covered. But first things first.
Mounting Your Data
The first to do is, to make your data accessible to the indexer.
[TODO]
Configuring Apache to Proxy the Documents
The quick hack is, to add your path to proxy in /etc/apache2/sites-available/000-default.conf
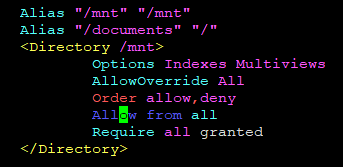
This allows the documents to be accessed throuch http://<IP_OF_YOUR_OSS>/documents/mnt but also through http://<IP_OF_YOUR_OSS>/mnt. We will secure this later on. But for debugging, this is quite helpful.
To get the links in OSS right, you need also to adjust /etc/opensemanticsearch/connector-files to have a line with the following content
config['mappings'] = { "/": "http://172.22.2.108/documents/" }
You can also add more mappings, but this helps to get it right for the links in OSS Web UI.
(Re-)Starting the OSS server
I would advise to do a simple reboot of your server, to also check, if the shares get mounted correcly. For my debian buster, this is not the case. It is failing to mount the NFS shares for some reason, I have not yet digged down. I manually mount it, after it has startet. I assume, the systemd start dependencies are a bit buggy.
[Much more to write on… Coming soon]
Troubleshooting
So, what to do, if something goes wrong? E.g. if your decided to index a ton of data, it is time to purge the queue. But how?
Purging the Queue
OpenSemanticSearch uses RabbitMQ to organize the indexing tasks. If OSS decides to index a path, it will simply list all files in this path and put it in the open_semantic_etl_tasks-Queue of your RabbitMQ server. But the user interface of OSS does not provide a means of purging or deleting the content of the queue. But therefore, you neet to activate the rabbitmq management web ui.
sudo rabbitmq-plugins enable rabbitmq_management
After this, you can check, if your server listens on the apropriate interface (0.0.0.0 for acces from another host) and port (15672)
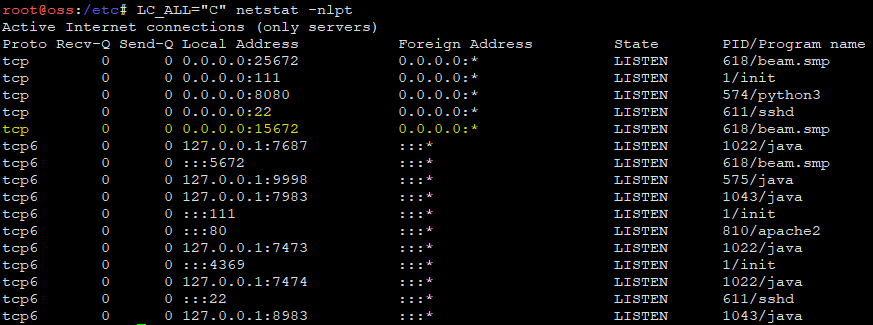
netstat -nlpt output of a typical OSS host with enabled RabbitMQ Web UIThis checked, we need to add a user with administrative rights to the OSS worker.
rabbitmqctl cluster_status # Check if everything is fine rabbitmqctl list_users # Check if your webuser doesn't exist rabbitmqctl add_user webuser <PASSWORD> rabbitmqctl set_user_tags webuser administrator rabbitmqctl set_permissions -p / webuser "." "." "."
This done, you can simply acces the user interface. Type in your browser http://<IP_OF_OSS_HOST>:15672/ and the login will be presented to you.
After loging in, head over to the queues and enter your open_semantic_etl_task-queue.
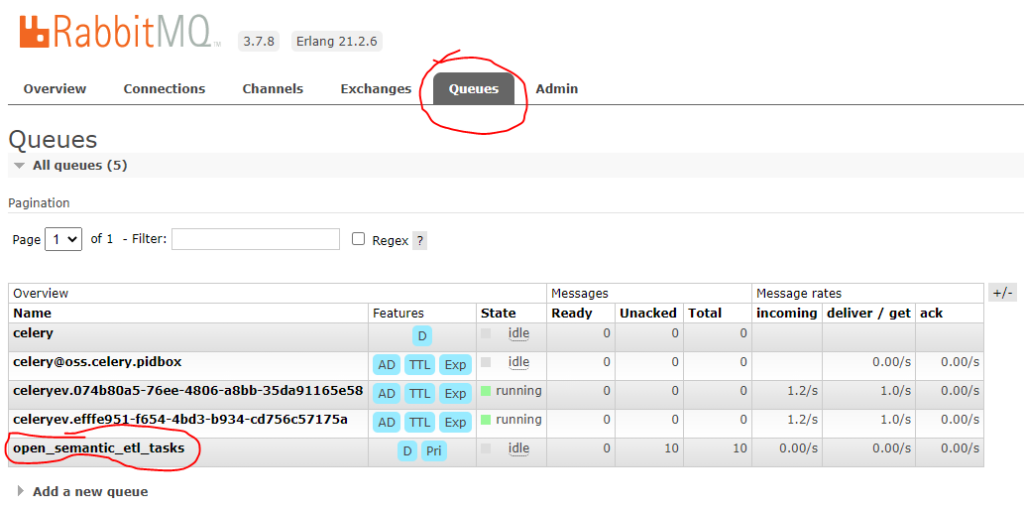
You should be presented with the queue details
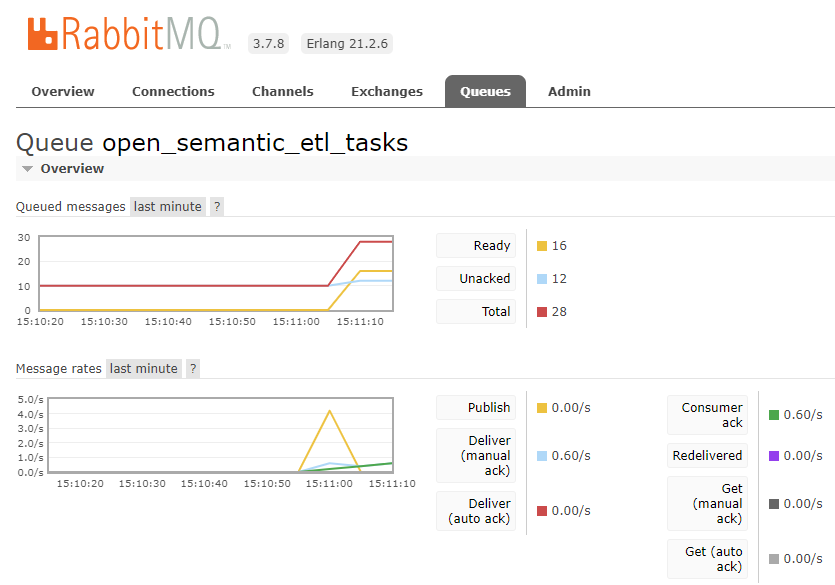
In my example, you can see a very limited count of ready tasks. This can go up to a few thousand tasks when indexing a large directory with many files. Each file will add a task to this queue and RabbitMQ will hand this out to the etl workers of OSS.
To delete all messages in the queue, you can simply hit the Purge Messages button.
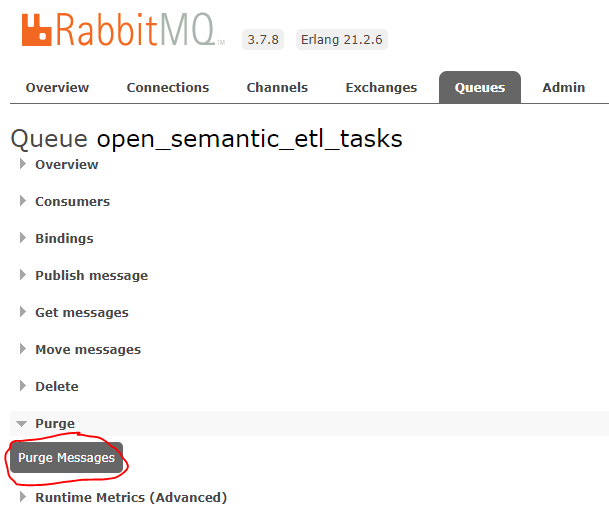
After this, you can re-enqueue the index files on your OSS search site through http://<IP_OF_OSS_HOST>/search-apps/files/
Schreibe einen Kommentar